How to Pivot to an AI-First Product: Lessons from Two CEOs

Alim Goulamhoussen
Publié le 12.06.26
6 min
Most content about AI pivots comes from consultants. This one comes from two founders who did it, got things wrong, and are still in the middle of it.
Charles Miglietti (CEO, Toucan) rebuilt the entire product from scratch. The legacy codebase made a real AI product impossible — starting over was the only option. Valentin Huang (CEO, Harvestr) integrated AI into an existing product. The foundations were solid. A full rebuild would have cost a year they didn't have.
Two different products, two completely opposite bets on the same problem. What follows is the debrief: the decisions that were hard to make, the mistakes neither team would repeat, and the early signals that told them they were on the right track.
This article is adapted from a live webinar. Watch the full replay here.

The moment each team knew they had to change
Charles (Toucan): The wall
The trigger wasn't a single event. It was slow accumulation. "Clients were asking almost every day: what's your AI roadmap? What will you do with AI? How can I see AI in your product?" For 9 to 12 months, the answer was always "coming soon." Mockups were built. The roadmap said it was planned. And then something more important always came up.

Until it couldn't be postponed anymore. New players were shipping compelling AI-native experiences. Existing competitors were announcing strong AI features. The question shifted from "should we do this?" to "what's the fastest and most durable way to build a true AI-native value proposition?"
The honest answer: layering AI onto the existing stack would take quarters, not weeks. The legacy architecture was the bottleneck. The rebuild wasn't a strategic choice — it was the only path to regaining speed.
Valentin (Harvestr): The foundation
Harvestr had identified the same problem before LLMs existed. A core part of their value proposition was helping product teams analyze customer feedback — text data. Machine learning could help, but it required a dedicated ML team they didn't have. So they waited.

Then ChatGPT happened. "We thought: this is a new technology to analyze, generate, and summarize text data. If we don't do it, it will disrupt us." The use cases were already mapped. The product foundations were solid. Rebuilding everything would have been slower, not faster.
Same starting problem. Different architecture. Different answer.
What they actually had to kill
Charles: Killing features is harder than it sounds
AI-accelerated coding creates a specific illusion: "You get a feeling that you can rebuild everything in a few weeks. That's partially true." The gap is completeness and stability in production — the kind you accumulate over years, not sprints.
Toucan intentionally removed features that had been built for specific customer types: many data connectors narrowed to data warehouses and SQL databases only; email notifications, scheduler, and export flows all dropped. The goal was to reduce complexity and focus on the core value proposition.
What survived: the query engine, the chart library, the multi-tenant architecture. These were kept and rebuilt around AI from the ground up — conversational analytics as the primary entry point, not an add-on.
Valentin: Sequencing AI into an existing product
For Harvestr, the approach was to map existing customer frustrations against new LLM capabilities and find the highest-impact matches at reasonable cost. "Implementing new features, even in the age of AI, is not free."
They started with feedback summaries — the easiest, most contained improvement. Then AI categorization. Then more core parts of the experience. Now: an agent within the product and an MCP integration.
The strategic frame was simple: which AI capabilities, if built by someone else, would disrupt them? That list became the prioritization grid.
What to tell existing customers
This question burns for most teams going through an AI pivot. Both answers were more honest than you'd expect.
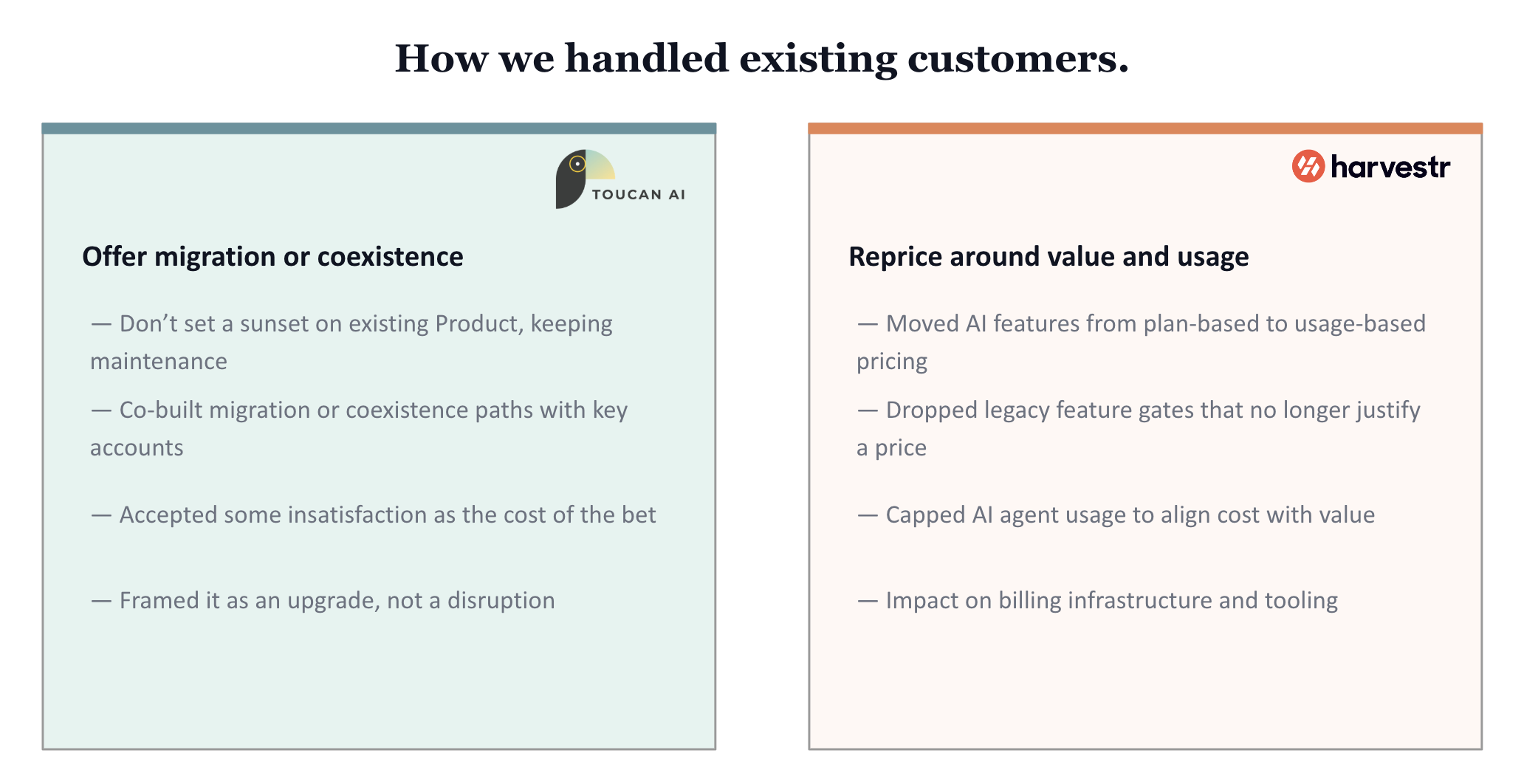
For Harvestr, the integration approach helped. Because AI was layered into existing workflows, customers didn't feel like the product changed underneath them. They just got better results from familiar features. Usage comparisons before and after AI integration became a direct proof point for the team, and for customers.
For Toucan, the communication is ongoing. The new product is positioned as the "spearhead of the future" — AI-first, mostly designed for embedded use cases. The legacy product is still maintained. The bridge between the two is being built. "Not every customer has the same problem Toucan AI is solving today."
Both teams had to revisit pricing. Harvestr moved from plan-based to usage-based pricing for AI features. They tested willingness to pay by adding AI only to the highest plans first. They eventually dropped their premium plan entirely. They also had to rebuild billing infrastructure to handle usage tracking — something worth thinking about before you start, not after.
Toucan shifted to usage-based tiers on AI, while maintaining the existing product for customers who haven't migrated.
What each team got wrong
Charles: Underestimating the organizational learning curve
"Building AI agents is not just about prompting an LLM." The harder part is everything around it: how you evaluate not just the model but the full workflow, how you orchestrate agents, how you build reliable feedback loops, how you approach determinism. These aren't hard to understand — they're just expensive to learn in practice.
The ecosystem, even now, is not well documented. Best practices are still emerging. What works today may not work next month. "Teams are still testing what works best, what the recommended architecture is. What's true one day might not be true the day after."
Toucan's lead developer learned a lot. He's still learning.
Valentin: Skipping evaluation systems to ship faster
Early on, Harvestr shipped AI features the same way they'd shipped everything else: test with a few customers, iterate, release. That was wrong.
"We didn't have the right evaluation system in place. And without it, you don't know what's working and what's not. You don't know what to improve next." Worse: customers who encountered inconsistent outputs lost trust in the AI features entirely and stopped using them.
The fix was building their own testing interface — running outputs against real customer data, either manually or at scale. Purpose-built, not off-the-shelf. At the time, no existing tool did exactly what they needed. Now it's the foundation of how every new AI feature is validated before shipping.
What actually worked
Charles: Conversational analytics as the primary entry point
The traditional analytics model starts with charts, dashboards, and filters. Toucan's bet was to flip the entry point: start with the conversation. Ask a question, get a visualization.
"Even before we had proper metrics, we could feel the reaction from prospects during demos. People immediately understood the value proposition." The resonance was there before the data was.
Today, with tools like ChatGPT and Cursor normalized for millions of professionals, the conversational interface doesn't need explanation. It's the expected pattern.
Valentin: Embedding AI in existing workflows, not alongside them
The decision not to build a parallel AI product was the right one. By improving AI within existing features, Harvestr preserved user habits. Customers didn't have to learn a new product. They just got better outputs from the one they already used.
This also made success measurable. Usage of specific features before and after AI integration is a direct indicator of whether AI is actually delivering value — not just being adopted because it's new.
If you're starting your AI pivot tomorrow
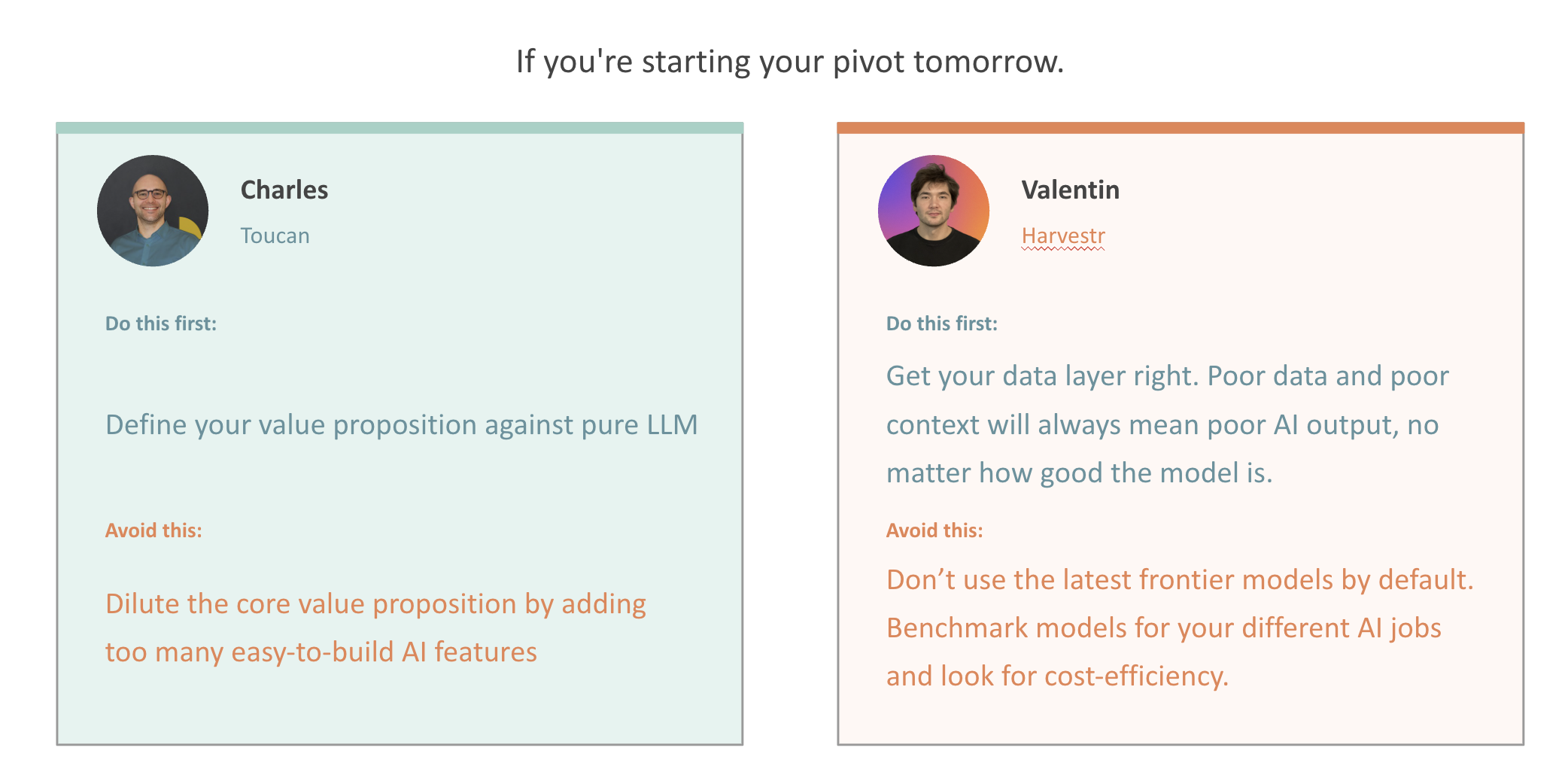
Both founders agreed on the framing: there is no universal answer. The right bet depends entirely on your context — what you've built, who your customers are, where you want to go.
But here are the things both would do from day one.
Charles's two pieces of advice
Define your moat against pure LLM. The question you'll hear from every prospect and customer: "Can I just do this in ChatGPT?" If you can't answer that clearly, you don't have a product — you have a wrapper. What can your product do that a raw language model can't? That answer needs to be specific, not vague.
Don't dilute your core value proposition. AI makes it easy to build features quickly. That's also the trap. Build too many AI features that aren't distinctly yours and you end up with nothing customers can't get elsewhere. Define what makes you unique and protect it.
Valentin's two pieces of advice
Get your data layer right first. Your moat isn't just the model — it's the data the model runs on. "With bad data, you will get bad results even with the latest, most powerful models." The data your customers have in your product is often not formatted correctly for the AI use case you're building. Fix that before testing models. It takes time. Do it anyway.
Don't underestimate the UX. Shipping an AI feature and building a good AI experience are two different things. The teams that win aren't the ones with the best model — they're the ones who've thought through how customers actually use the feature day to day, and made that experience better than what they'd get from ChatGPT or Claude directly. That takes iterations, not just a model choice.
A note on team dynamics
Both founders were asked how they handled the internal transition: engineering, sales, customer success.
For Charles, sales enablement was the immediate priority: battle cards, product marketing materials, answers to every question a prospect might ask. Engineering moved more slowly — starting with a squad of three or four people before expanding to the full R&D team over several months. The new tech stack required time to learn properly.
For Valentin, the key was identifying early adopters within product and engineering teams and giving them the resources to bring the rest of the company along. "Product and engineering are usually the early adopters of AI. Find your champions and give them the means to spread it."
The honest debrief
One full rebuild. One progressive integration. Both teams got things wrong. Both teams found things that worked. Neither is finished.
The useful takeaway isn't which approach was correct. It's that the decision was contextual. Toucan's legacy architecture was a wall. Harvestr's was a foundation. The same external pressure — the AI wave — produced two completely different, equally valid responses.
What matters is the discipline: know your data before your model, define your moat before your feature list, build evaluation before you ship at scale. And don't mistake the ease of building AI features for the difficulty of building AI products.
Those are harder to build. They always were.
Go deeper
- Analytics Solution: Should You Build or Buy? — The full breakdown of build vs. buy for ISV teams evaluating embedded analytics.
- The Ultimate Guide to Embedded Analytics — Context on what embedded analytics means and why ISVs invest in it.
- How to Generate New Revenue Streams with Data in a SaaS Product — How analytics features translate into retention and monetization.
- Self-Service Analytics: Benefits and Challenges — Why self-service has changed with AI, and what teams need to get right.
Want to see what Toucan's AI-first rebuild looks like in practice? Book a demo or try for free and we'll show you the conversational analytics layer — no slides, no pitch, just the product.