Understanding Failure Metrics: MTTR vs. MTBF vs. MTTF
.png?width=88&height=88&name=portrait_agathe_face%20(1).png)
Agathe Huez
Publié le 11.05.22
Mis à jour le 13.01.26
5 min
Metrics are the cornerstone in evaluating the success or failure of any project. Since success is the end goal of every project, we often forget to look into failure metrics. Most companies fail to analyze failure and thus fail to account for it on most projects. To understand failure metrics we will have to start by understanding failure itself, or rather how we should define it.
Maybe you think that failure is obvious, and we shouldn’t waste any time discussing such a basic concept. When something doesn’t work, it means that it’s failed. Right? According to Wikipedia failure is defined as:
The state or condition of not meeting a desirable or intended objective.
Though it is a straightforward definition there is much room for interpretation. Take for example a hip-hop single for a famous artist that received multiple awards and was acclaimed by critics but failed to sell over 100,000 copies. Was this a success or failure?
This can be extended into the software world. Imagine an analytics application that always gives you the correct results. But with a complicated interface, it is very difficult to use for most users who aren’t data experts. This makes it so that the adoption rate of the application in any organization is below 25%. Now would this application be considered a success or failure?
In my eyes, the analytics application would be considered a failure. Even though the results are always accurate, if they cannot deliver insights to the team, it is nothing more than “fun fact” that a few users in the organization know. Now that we have understood what would be considered a failure, let's get to the crux of this blog post, the metrics. We must find a way to put subjectivity aside and come up with a measurable definition of failure. When it comes to the technology world—and this is especially true when it comes to the hardware, infrastructure, and operations side of things—the most popular way to measure failure is through system outages or downtimes.
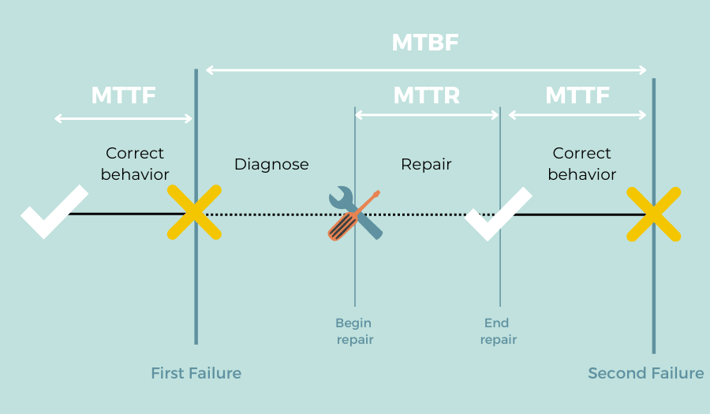
The most important failure metrics to consider in every project are MTTR, MTBF, and MTTF. MTTR stands for “mean time to repair.” MTBF is the acronym for “mean time between failures,” and finally, MTTF means “mean time to fix.” All three of them indicate a certain length of time.
So how different—or not—are these metrics from each other? Is there any difference between “repairing” and “fixing”? What qualifies as a failure? These are the kinds of questions we’ll be answering today. Let’s dig in.
MTTR vs. MTBF vs. MTTF
In order to improve in any project you are currently working on, you need objective indicators that you can keep track of and improve. Around the world, organizations make significant investments in their technology infrastructures. So not employing metrics to monitor and improve them is literally not caring about the ROI.
After talking about the importance of defining failure in an objective way and explaining why keeping track of metrics is so essential for organizations, it’s time to cover the metrics and how to calculate it.
MTTR (Mean Time to Repair)
Mean time to repair (MTTR) is a basic measure of the maintainability of repairable items. It represents the average time required to repair a failed component, device, code or solution.
MTTR shows the time it takes to react to unplanned incidents and put equipment or devices back to work again. This metric calculates the time passed from the beginning of an incident until the moment it’s solved.
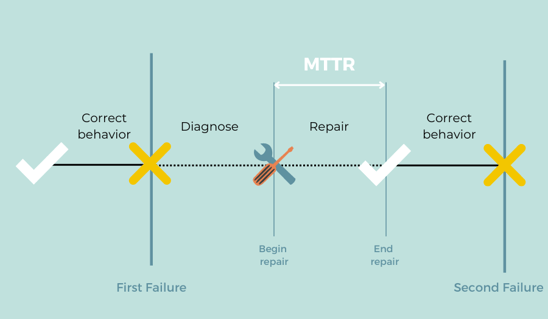
Why Should You Care About MTTR?
By tracking it you can find how fast your organization responds to problems thrown it's way. The smaller the number the better. Knowing this number will allows you to balance customer and employee expectations when problems arise.
MTTR often includes the time to do the following:
- Notify the relevant repair workers.
- Diagnose the problem.
- Repair the problem.
- In the case of code, fix the bugs.
- In the case of code test to make sure repairs haven’t affected other parts of the program.
- In the case of physical equipment, allow the equipment/devices to cool down.
- In the case of physical equipment, reassemble the device and make it ready for use again.
- Finally, set up and test the device.
How to Calculate MTTR
Calculating the mean time to repair is simple. First, you find out the total time spent on unplanned maintenance for a given asset (e.g., a specific device). Then you divide that number by the number of failures that happened with that equipment over a specified period of time.

Imagine your organization spent 30 hours fixing the broken analytics you built. Such bugs have occurred 5 times during the year. That means that your MTTR is 6.
What’s a desirable goal for your MTTR? That varies a lot, especially depending on the type and size of the organization. MTTR value of 5 hours or less is considered a good goal.
MTBF (Mean Time Between Failures)
MTBF is all about the devices themselves. While MTTR represents how quickly an organization can react when unexpected problems occur, MTBF indicates the level of quality and reliability of assets.
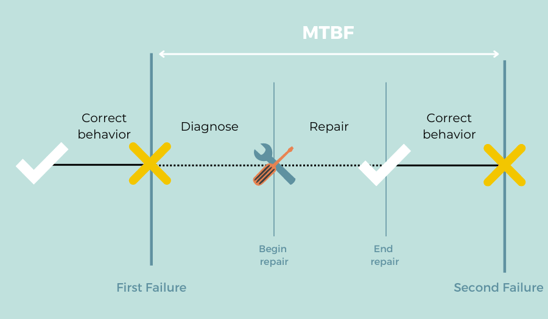
Why Should You Care About MTBF?
For starters, you track MTBF so you can improve it. Improving MTBF means increasing the time between failures. This can mean that fewer incidents are happening or that they’re being solved quicker. MTBF measures reliability. So, by carefully monitoring this metric, you’ll be able to know the expected life span of a given asset.
Once you have this knowledge, your organization can use it to make educated decisions on issues such as scheduling of maintenance, inventory management, and so on.
MTBF, along with other KPIs, can also help your organization evaluate its own monitoring capabilities. If your organization already adopts monitoring tools and mechanisms, keeping your MTBF high shouldn’t be so hard.
How to Calculate MTBF
Calculating MTBF is also simple. First, you find the total number of operational (online) hours for a given asset over a given period. Then you divide that number by the number of failures that happened over the same time.

So imagine that aa equipment has been fully operational for 3,000 hours over a period of 12 months. Over the same period, that asset broke down 3 times. The MTBF for this piece of equipment, then, is 1,000 hours.
MTTF (Mean Time to Failure)
MTTF stands for “mean time to failure.” In short, this metric refers to the average life span of a given asset.
The only major difference between MTBF and MTTF is that MTBF is usually reserved for repairable items. MTTF, on the other hand, is used in scenarios where fixing an item isn’t an option.
We can say that MTTF represents an expectation. It sets the amount of time you can expect a given asset to work reliably until it fails.
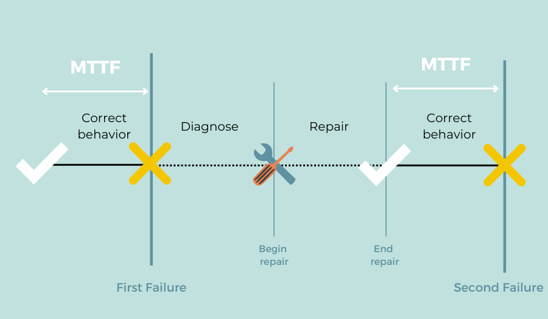
Why Should You Care About MTTF?
Like MTBF, MTTF indicates reliability. By tracking this metric, you’ll be able to get an accurate estimate of how long a given item works until it breaks beyond repair. MTTF helps organizations make informed decisions about inventory management—even including decisions about which brands to buy—and more.
MTTF relies on another very important metric we’re not discussing today: MTTD. MTTD stands for “mean time to detect” and refers to the average time it takes your organization to become aware of incidents when they happen. Keeping MTTD low is the key to managing all of the other metrics.
How to Calculate MTTF
You calculate MTTF by taking the total number of operational hours and dividing them by the number of assets you’re monitoring.

Let’s say we have 8 pieces of equipment we’re testing. The first one failed after 32 hours, while the second one failed after 12 hours. The third failed after 80 hours, and finally, the last one failed at eight hours. So we have a total uptime of 36 hours, which divided by 8 equals 20 hours. This result suggests this particular asset will need to be replaced, on average, every 20 hours.
MTTR vs. MTBF vs. MTTF: Which is the Most Important
In short, DevOps is about action. It’s not about measuring for the sake of measuring. For DevOps, metrics are only useful when they’re actionable—that is, when they help your organization make decisions and fix problems.
MTTR is a way more attractive metric. MTBF and MTTF, as you’ve seen, are more focused on figuring out the expected life span of assets. You could say that they’re more passive. MTTR, on the other hand, is all about action. It’s an incentive for your organization to go out there and fix whatever’s wrong. That’s absolutely the attitude you want from an organization that performs DevOps.
In the end, to track any metric reliably you need a trusted analytics platform, that can not only compute data but also display it in a way that everyone in the organization can understand. This is where Toucan comes in with its guided analytics and data storytelling. This way your metrics can be seen and understood by the users that it affects the most and easily communicate to anyone within the organization.
.png?width=112&height=112&name=portrait_agathe_face%20(1).png)