New hybrid data pipelines: unleash the power of YouPrep on any data source
.jpg?width=88&height=88&name=PORTRAIT_David_face%20(1).jpg)
David Nowinsky
Publié le 22.02.24
Mis à jour le 13.01.26
2 min
With the new release of Toucan this month, we’re introducing a new concept that will break barriers for app builders.
The Problem(s)
One can prepare data easily in Toucan using a visual query builder. The pipelines are then translated to a query suited for the source, such as MongoDB aggregation pipeline or a SQL query in the appropriate dialect. If the source doesn't have a specific translator, it’s no big deal: we’re extracting the source data with one of our connectors, and then transforming it in memory, with pandas.
However, it isn’t easy to make sure every translator supports the same set of features. Sometimes, it’s even not possible due to limitations of the target databases. And it could be frustrating to search for the perfect transformation step, only to see it’s not supported .
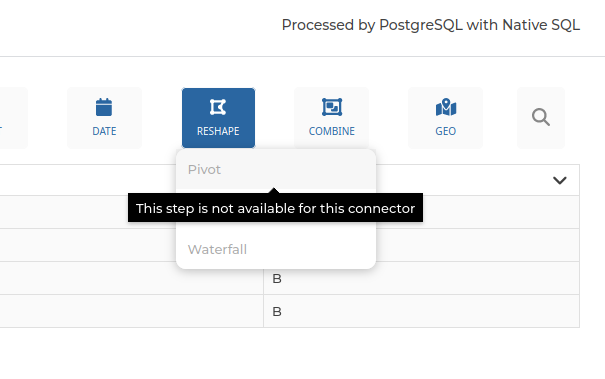
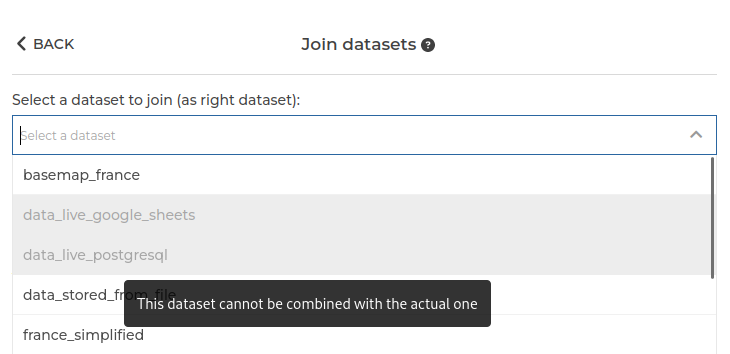
Another problem could arise when trying to join datasets coming from different sources. It seems obvious that an SQL query to a PostgreSQL database won’t execute a join with a dataset coming from an HTTP API, but our UI would have made it so simple to join any dataset with any other, that it almost feels like a bug. There are plenty of good use cases for these, such as having referential data from a file that doesn’t change often, and transactional data from a transactional database. Or having a file with geographical features, and wanting to join them with data that correspond to these zones.
The solution
At Toucan, our obsession is to keep things dead simple for our users. With this principle, it quickly became obvious that these limitations had to be lifted.
To tackle this, we’ve developed a query planner, which will determine which steps can be translated to be executed by the database, and which cannot and will be executed in memory.
Let’s say we would like to display the evolution of the yearly sales per customer. We could create visually a pipeline like this:
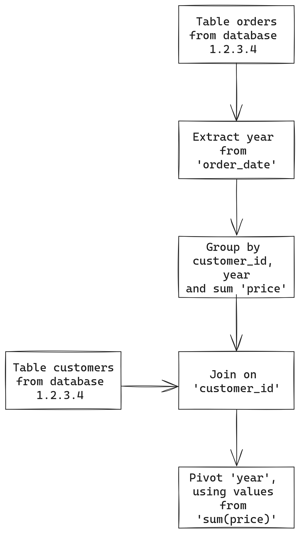
To plan how to execute this pipeline, our new planner will check step by step which ones can be pushed to the source database. In our example, let’s say it’s a PostgreSQL database hosted at the address 1.2.3.4.
In this example, all the steps can be converted to SQL, except the pivot. Previously, we would have disabled the pivot step when creating the pipeline, but now it’s possible thanks to our in-memory engine. The resulting plan would be:
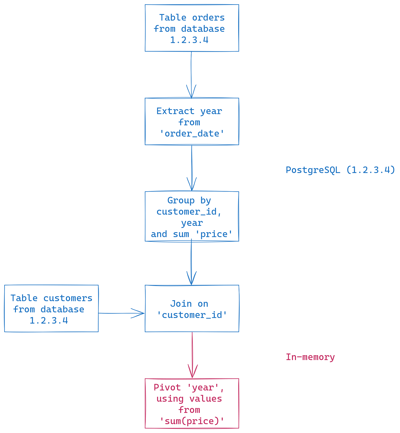
could be executed by the source database except the last one.
But what if your table resides in another database? Previously, you would not be able to join them directly in Toucan. Maybe you would have to set up an import from one database to another. Or maybe you could import them both to Toucan’s data store, but for huge datasets or cases where data should be instantly refreshed, that would not be an option. Now, our planner will execute both queries on both databases and join them in memory.
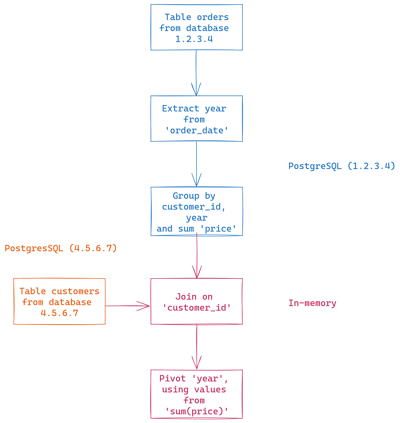
Plan for a pipeline with data coming
from different databases
By determining automatically how to execute these queries from different sources with different engines, we’re hiding the complexity of where is data and how to process it from users, so they can focus on more important topics, such as which indicator should be presented and what are the rules to compute it.
What's Next?
Our journey to simplify the data processing powering your analytics is far from over. We are exploring new avenues to further simplify and enhance it, such as:
- Providing execution information and performance metrics for pipelines to aid in debugging and optimization
- Visualizing the data flows you created using interactive graphs
- Empowering users to selectively override the query planner's decisions for specific steps
- Caching planning and translation steps to boost performance
- Continuously improving the performance of the query executor (spoiler: we’re already working on it
)
Stay tuned for future releases!
.jpg?width=112&height=112&name=PORTRAIT_David_face%20(1).jpg)