



A priori, rien de plus simple que d’insérer des données dans une base mongo :
>>> import pandas as pd
>>> import pymongo
>>> collection = pymongo.MongoClient()['testdb']['testcollection']
>>> df = pd.DataFrame({
... 'x': ['spam', 'bacon', 'eggs'],
... 'y': [42.0, True, None],
... })
>>> records = df.to_dict(orient='records')
>>> collection.insert_many(records)
>>> collection.find_one({"x": "spam"})
{'_id': ObjectId('59b1388f5e370e26165e6e59'), 'x': 'spam', 'y': 42.0}
Cependant, si cette simple approche suffit pour de petites quantités de données, de nouveaux problèmes surviennent quand les données grossissent :
- la conversion du dataframe en dictionnaire fait exploser la mémoire ;
- l’insertion des données prend plusieurs heures.
Voici donc un bref retour d’expérience sur la manière dont nous sommes passés d’un système sans gestion d’erreur ni scalabilité à une solution 10 fois plus rapide − et quels problèmes nous avons rencontré au passage.
Limitation de la mémoire
Face au premier point, un pattern vient rapidement à l’esprit : insérer les données bloc par bloc, et non d’une traite. On peut pour cela manipuler des slices du DataFrame au lieu du DataFrame entier :
slice1 = df[:10] # les 10 premières lignes slice2 = df[10:20] # les 10 suivantes Manipuler des slices de DataFrame a l’avantage de ne pas créer de copie des données en mémoire. Avec un générateur de slices tel que :
def slice_generator(df, chunk_size=10):
current_row = 0
total_rows = df.shape[0]
while current_row < total_rows:
yield df[current_row:current_row + chunk_size]
current_row += chunk_size
on peut facilement insérer les données bloc par bloc :
for df_chunk in slice_generator(df):
records = df_chunk.to_dict(orient='records')
collection.insert_many(records)
La transformation du DataFrame en liste de dictionnaires crée une copie des données en mémoire, mais avec cette solution, la mémoire n’explose pas, la mémoire utilisée étant libérée entre chaque bloc (si le serveur MongoDB est lancé sur la même machine qui exécute ce code, la consommation mémoire de MongoDB, elle, va augmenter).
Un autre avantage de processer les données bloc par bloc est de pouvoir dumper seulement un bloc de données si une exception survient lors de l’insertion. Il est alors plus facile d’examiner les données et de trouver les fautives.
La taille de bloc choisie dans l’exemple ci-dessus est évidemment bien trop petite dans la plupart des cas : le code passerait la majorité de son temps à boucler plutôt qu’à insérer réellement les données. La taille idéale dépendra des ressources matérielles et de la configuration de MongoDB ainsi que du format des données (de la taille d’une ligne de donnée, notamment).
Accélération de l’insertion
À ce point, l’insertion des données est toujours très lente. Bien entendu il n’existe pas de solution miracle à ce problème, le temps d’insertion reste proportionnel à la quantité de données à insérer. Mais en l’état, la limitation de la vitesse d’insertion ne provient pas d’une saturation de la bande passante (réseau) ou de la capacité de MongoDB à recevoir les données qu’on lui envoie. On peut accélérer l’insertion en parallélisant l’envoi des données.
Un benchmark basique (à coup de log des temps écoulés) sur un de nos jeux de données nous indique que l’étape “to_dict” de transformation du DataFrame en liste de dictionnaires est aussi chronophage que l’étape d’insertion proprement dite.
On utilise le multiprocessing avec le modèle suivant :
- le processus “principal” envoie des chunks de dataframe dans une queue (
multiprocessing.Queue) Q1 - on a un pool P1 de workers (
multiprocessing.Process) attendant l’arrivée de messages dans Q1. Chacun de ces workers exécute ce code:while True: df_chunk = Q1.get() records = df_chunk.to_dict(orient='records') Q2.put(records) - on a un second pool P2 de workers attendant l’arrivée de messages dans Q2. Chacun de ces workers exécute ce code:
while True: records = Q2.get() collection.insert_many(records)
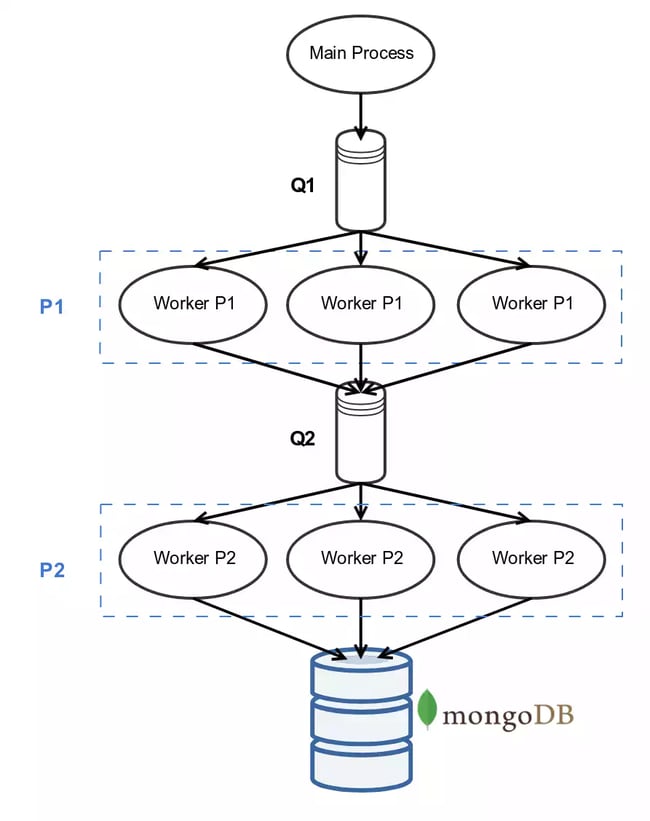
Théoriquement, plus on aura de workers, plus l’insertion se fera rapidement (jusqu’à ce qu’on atteigne un seuil où le goulot d’étranglement sera la bande passante ou bien MongoDB lui même). D’un autre côté, plus on aura de workers, plus on consommera de mémoire, puisque chaque worker utilise une quantité de mémoire proportionnelle au bloc de données qu’il traite. On s’attend cependant à avoir une consommation de mémoire stable pendant la durée de l’insertion (toujours à la condition que le serveur MongoDB soit sur une autre machine).
Chasse à la fuite de mémoire
Alors, est-ce que la consommation mémoire reste stable, comme attendu ? Hélas, on se retrouve face à deux mesures qui semblent contradictoires.
La première est donnée par la commande grep MemFree /proc/meminfo, qui nous indique que la mémoire libre sur la machine ne fait que diminuer, pendant toute la durée de l’insertion.
La seconde mesure est obtenue grâce au module python psutil, en loggant l’usage mémoire au sein des différents workers, via psutil.Process(os.getpid()).memory_info(). L’usage mémoire de chaque worker semble stable ! Par ailleurs, l’usage mémoire de chaque worker semble beaucoup plus élevé que la taille du chunk en cours de traitement : on dirait plutôt la taille du DataFrame original entier, ce qui semble farfelu puisque la machine ne disposerait pas d’assez de RAM pour exécuter autant de workers s’ils étaient si gourmands.
Que se passe-t-il en réalité ?
La façon dont est créé un processus multiprocessing.Process (sous GNU/Linux) est un fork du processus principal. Suite à cette opération, on obtient 2 processus : le parent et le fils. À ce moment là, chacun d’eux “voit” la même zone mémoire, et a l’impression qu’il s’agit de la sienne, propre. En réalité, la zone mémoire n’a pas été dédoublée, elle est accessible en lecture-seule pour les 2 processus. Mais dès que l’un des deux processus tente d’écrire sur cette zone mémoire, la portion concernée est copiée, et le processus écrit alors sur une zone mémoire qui lui est propre, et non accessible à l’autre.
Dans notre cas, cette explication paraît tout de même insuffisante : ni le processus parent ni les workers ne sont censés écrire sur la zone mémoire partagée, pendant l’étape d’insertion :
- le processus parent ne fait que lire des portions du DataFrame (dans la mémoire partagée) et les insérer dans une queue
- le worker ne fait que lire et écrire dans une queue
Or les queues sont un mécanisme de communication inter-processus différent de la mémoire partagée.
Le coupable : python. L’interpréteur python tient à jour un compteur de référence pour chaque objet : cela lui est utile pour le garbage collector. L’inconvénient, c’est que lors d’un simple accès en lecture sur un objet (une simple assignation de variable x = mon_objet), ce compteur de référence est incrémenté : on a donc une écriture sur la zone mémoire. Le mécanisme décrit plus haut, appelé copy-on-write, devient du copy-on-read avec python.
Pour éviter cet écueil, une solution potentielle serait de créer non pas les workers via un fork mais via un spawn : le processus ainsi créé ne verrait pas la zone mémoire de son parent, ce dernier pouvant continuer à écrire dessus sans surcoût. Mais cette possibilité (multiprocessing.set_start_method('spawn')) n’est disponible que dans python 3, or notre codebase était encore en python 2 à l’époque où nous avons été confronté à ce problème.
La solution que nous avons retenue a donc été la suivante : créer les workers avant de créer le gros DataFrame. De cette manière, le gros DataFrame ne fait pas partie de la mémoire partagée.
Intégration dans une task celery
Le proof-of-concept de l’insertion parallèle semblait fonctionnel, il ne restait plus qu’à l’intégrer à notre codebase en remplacement de la méthode d’insertion existante. Quand soudain :

L’usage de multiprocessing.Process était impossible dans celery. Heureusement, billiard.Process (billiard est un fork de multiprocessing utilisé par celery), lui, fonctionne, avec la même API !
Après quelques configurations (nombre de workers, taille des blocs, taille des Queue), nous arrivons finalement à des durées d’insertion 10 fois plus courtes qu’auparavant :-)